本篇Blog针对MindSpore v0.2.0版本的代码流程进行端到端讲解,详情请查阅MindSpore机器之心线上公开课第三讲:MindSpore代码流程分析。
术语
| 术语名称 | 支持列表 | 描述信息 |
|---|---|---|
| device_target | Ascend, GPU, CPU | 用户在运行MindSpore命令时,需要在context中指定后端设备类型 |
| execution_mode | Graph, PyNative | 用户在运行MindSpore命令时,可在context中指定运行模式 |
| dataset_sink_mode | True, False | 用户在调用模型train接口时手动指定数据集下沉模式:当前PyNative模式下不支持,同时CPU后端也不支持 |
| amp_train_level | O0, O2 | 用于用户指定自动混合精度的等级,O0:fp32,O2:fp16 |
| multi_graph_sink | Ascend | 图下沉模式,将整图下沉到Device侧执行,减少了Host与Device侧之间频繁交互造成的性能损耗 |
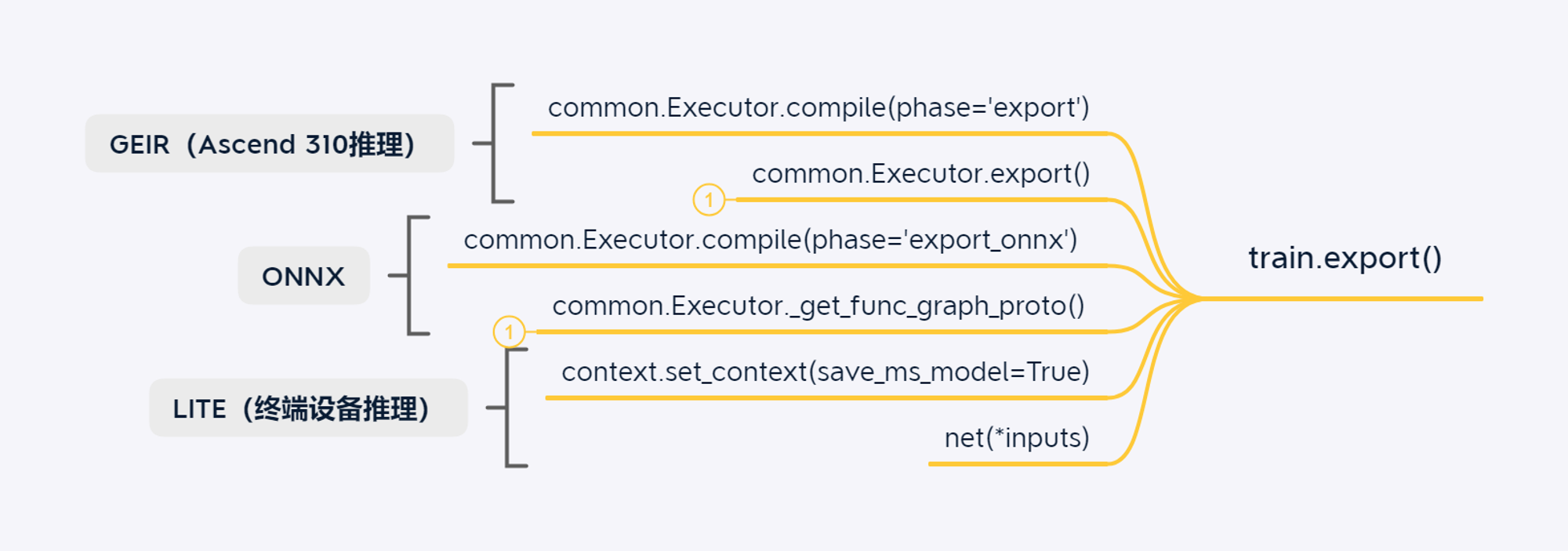
| export_mode | GEIR, ONNX, LITE | 在图导出过程中,用户可指定导出的模型类型:GEIR (Ascend310), ONNX (TensorRT), LITE (Android) |
| save_ms_model | LITE | 用户调用export()方法导出LITE模型时,需要在context中配置save_ms_model参数 |
MindSpore简介
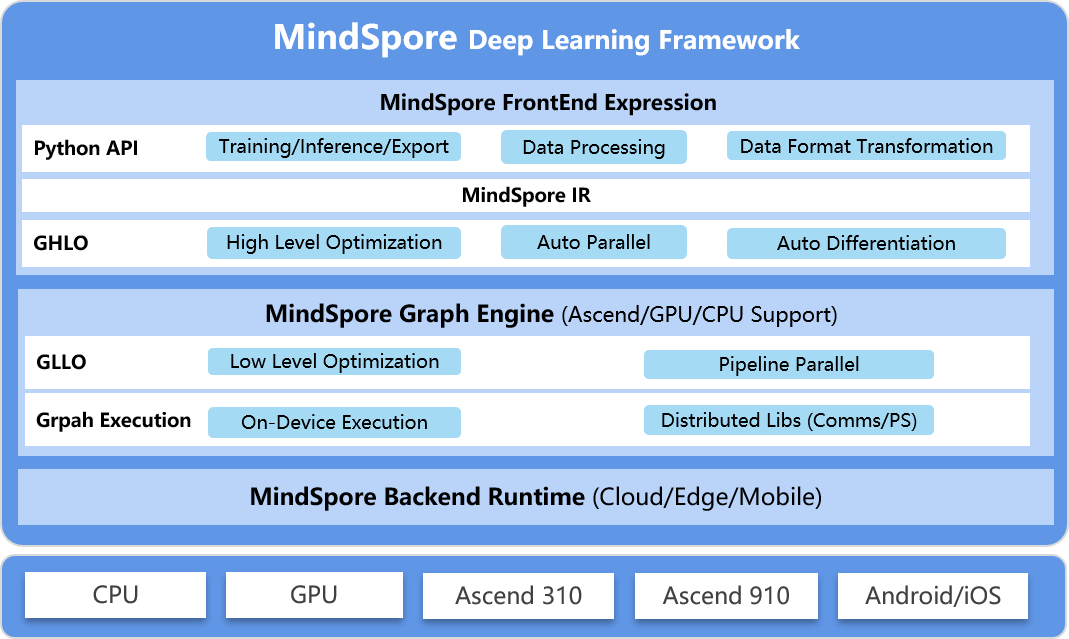
如MindSpore官方介绍,MindSpore主要分为FrontEnd和GraphEngine两大模块:
- FrontEnd为MindSpore前端表示层,包括Python API、MindSpore IR定义和GHLO (Graph High Level Optimization)三部分,其中后两部分均用C++语言编写,并通过
pybind11与Python部分衔接; - GraphEngine为MindSpore计算图引擎,负责计算图的执行逻辑,详见MindSpore机器之心线上公开课第二讲:GraphEngine浅析。
MindSpore组织结构
样例代码
example/
├── alexnet_cifar10
├── Bert_NEZHA_cnwiki
├── lenet_mnist
├── mobilenetv2_imagenet2012
├── resnet101_imagenet
├── resnet50_cifar10
├── vgg16_cifar10
└── yolov3_coco2017
mindspore/model_zoo/
├── alexnet.py
├── Bert_NEZHA
├── lenet.py
├── mobilenet.py
├── resnet.py
├── vgg.py
└── yolov3.py
| 模型&数据集 | 硬件平台支持 | 分布式训练 | ONNX Exporter |
|---|---|---|---|
| alexnet_cifar10 | Ascend, GPU | — | ✔️ |
| Bert_NEZHA_cnwiki | Ascend | — | — |
| lenet_mnist | Ascend, GPU, CPU | — | ✔️ |
| mobilenetv2_imagenet2012 | Ascend | — | — |
| resnet50_cifar10 | Ascend, GPU | ✔️ | ✔️ |
| resnet101_imagenet | Ascend | ✔️ | — |
| vgg16_cifar10 | Ascend | ✔️ | ✔️ |
| yolov3_coco2017 | Ascend | ✔️ | — |
NOTICE: 当前LeNet网络支持Ascend、GPU和CPU后端的训练,欢迎大家进行试用。
Python API
- 设置运行环境变量
mindspore/ └── context.pyimport mindspore.context as context context.set_context(mode=context.GRAPH_MODE) context.set_context(device_target="GPU") context.set_auto_parallel_context(device_num=8) context.set_auto_parallel_context(parallel_mode="auto_parallel") - 模型/网络API
mindspore/train/ ├── model.py └── serialization.py mindspore/nn/ ├── layer ├── loss ├── metrics ├── optim ├── wrap ├── cell.py └── dynamic_lr.pyimport mindspore.nn as nn from mindspore.train import Model from mindspore.train.serialization import export net = Net() loss = nn.SoftmaxCrossEntropyWithLogits() optim = Momentum(params=net.trainable_params(), learning_rate=0.1, momentum=0.9) model = Model(net, loss_fn=loss, optimizer=optim, metrics=None) model.train(2, get_train_dataset()) # Model train API model.eval(get_eval_dataset()) # Model evaluate API model.predict(get_predict_dataset()) # Model predict API # Export model to ONNX format export(net, get_input_data(), file_name='net.onnx', file_format='ONNX') - 算子调用API
mindspore/ops/ ├── composite ├── operations ├── functional.py └── primitive.pyimport numpy as np import mindspore.context as context import mindspore.nn as nn from mindspore import Tensor from mindspore.ops import operations as P from mindspore.ops import functional as F context.set_context(device_target="GPU") # ==================================================== # Usecase 1: run single op in PyNative mode by default # ==================================================== x = Tensor(np.ones([1, 3, 3, 4]).astype(np.float32)) y = Tensor(np.ones([1, 3, 3, 4]).astype(np.float32)) print(F.tensor_add(x, y)) # ==================================================== # Usecase 2: run single op in Graph mode by default # ==================================================== class Concat(nn.Cell): def __init__(self): super(Concat, self).__init__() self.cat = P.Concat() self.data1 = Tensor(np.array([[0, 1], [2, 1]]).astype(np.int32)) self.data2 = Tensor(np.array([[0, 1], [2, 1]]).astype(np.int32)) def construct(self): return self.cat((self.data1, self.data2)) cat = Concat() print(cat()) - 分布式训练API
mindspore/communication/ └── management.pyimport numpy as np import mindspore.context as context import mindspore.nn as nn from mindspore import Tensor from mindspore.ops import operations as P from mindspore.communication import init, NCCL_WORLD_COMM_GROUP context.set_context(mode=context.GRAPH_MODE, device_target='GPU') init('nccl') class Net(nn.Cell): def __init__(self): super(Net, self).__init__() self.allreduce_sum = P.AllReduce(P.ReduceOp.SUM, group=NCCL_WORLD_COMM_GROUP) def construct(self, x): return self.allreduce_sum(x) input_data = Tensor(np.ones([2, 8]).astype(np.float32)) net = Net() print(net(input_data))
C++组件
mindspore/ccsrc/
├── dataset
├── debug
├── device
│ ├── ascend
│ ├── cpu
│ └── gpu
├── ir
├── kernel
│ ├── aicpu
│ ├── cpu
│ ├── gpu
│ ├── hccl
│ └── tbe
├── mindrecord
├── onnx
├── operator
├── optimizer
├── parallel
├── pipeline
├── pre_activate
│ ├── ascend
│ ├── mem_reuse
│ └── pass
├── predict
├── pynative
├── session
├── transform
└── vm
| 模块名 | 描述 |
|---|---|
| dataset | 数据集操作的C++实现部分 |
| device | MindSpore后端设备管理模块,支持CPU、GPU和Ascend |
| ir | MindSpore IR定义,为pipeline提供统一中间表示 |
| kernel | MindSpore后端算子实现,支持AICPU、CPU、GPU、HCCL和TBE |
| onnx | ONNX Exporter模块,实现将MindSpore导出成ONNX模型 |
| operator | MindSpore算子定义的接口模块,所有算子继承了IR中的Primitive语义 |
| parallel | MindSpore自动并行模块,支持模型并行、数据并行等 |
| pipeline | MindSpore计算图编译的流水线定义,借鉴了LLVM经典编译器的设计理念 |
| pre_activate | MindSpore后端图执行前的准备工作,包括内存复用、GLLO、IR Fusion等 |
| predict | LITE Exporter模块,实现将MindSpore导出成LITE模型用于端侧推理场景 |
| pynative | PyNative模式的执行模块,根据后端设备类型执行不同逻辑 |
| session | 后端设备的管理接口,用于对外暴露device的管理操作 |
代码调用流程
CPU模型训练场景
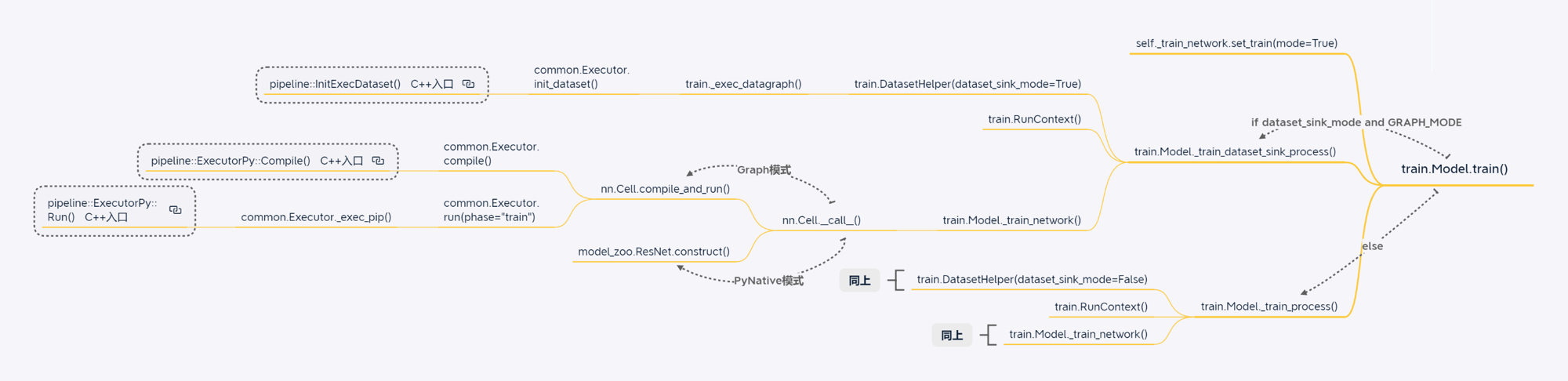
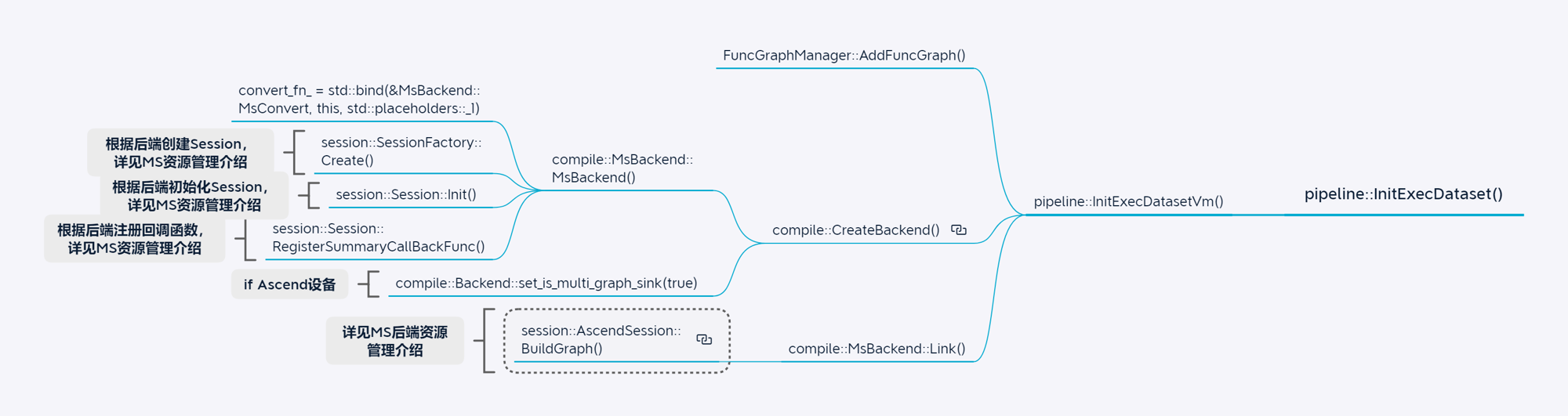
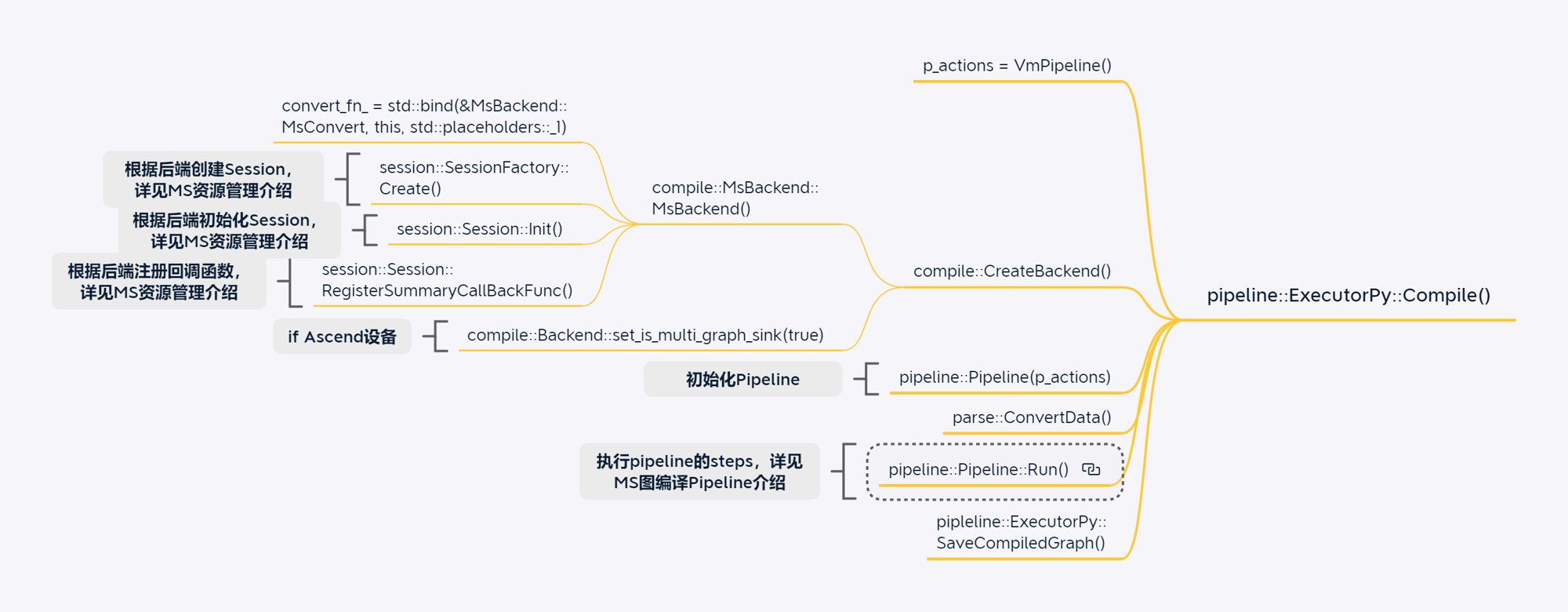
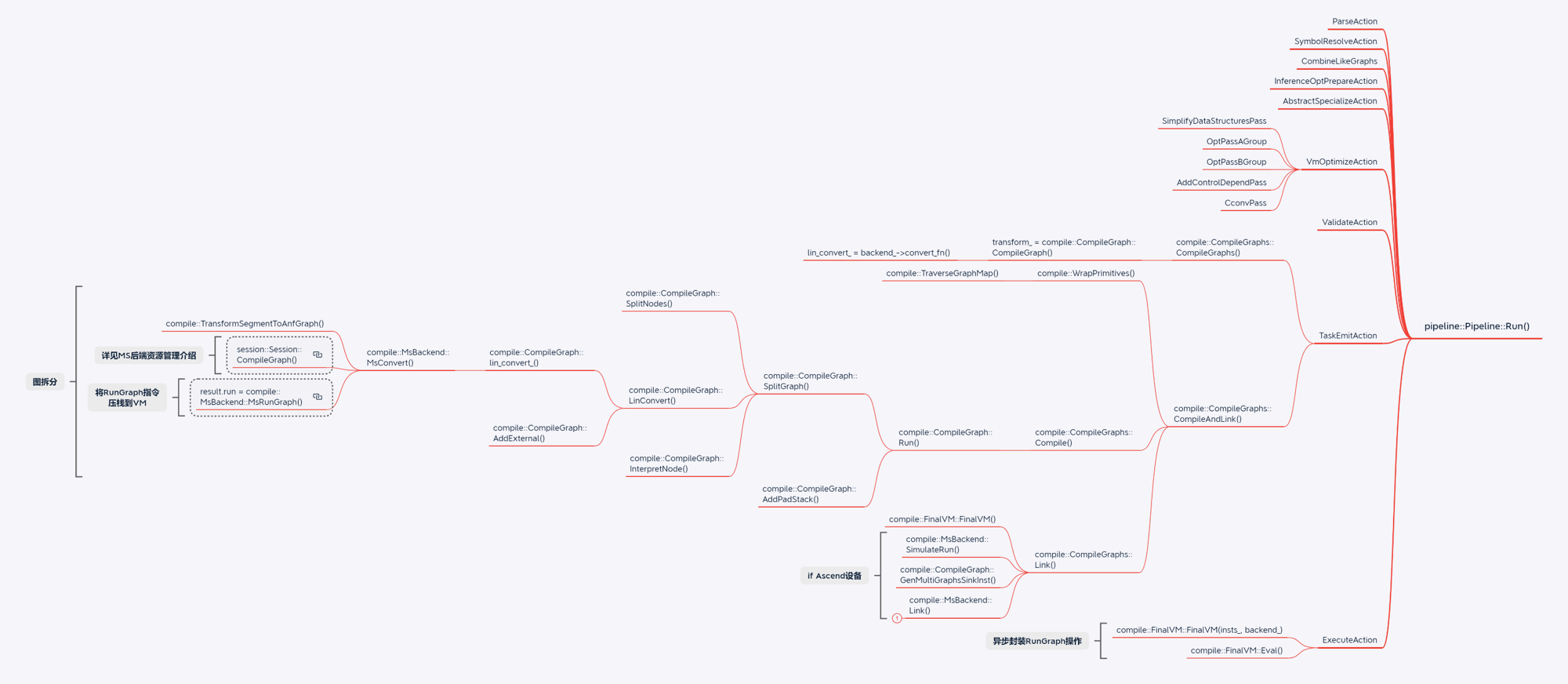
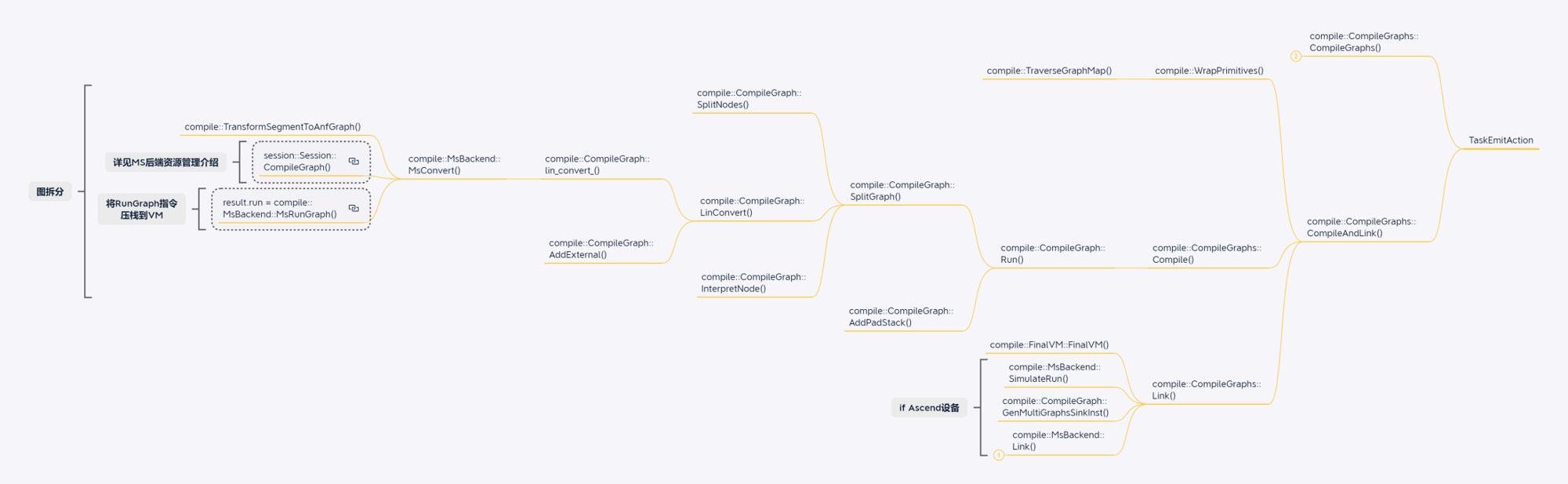
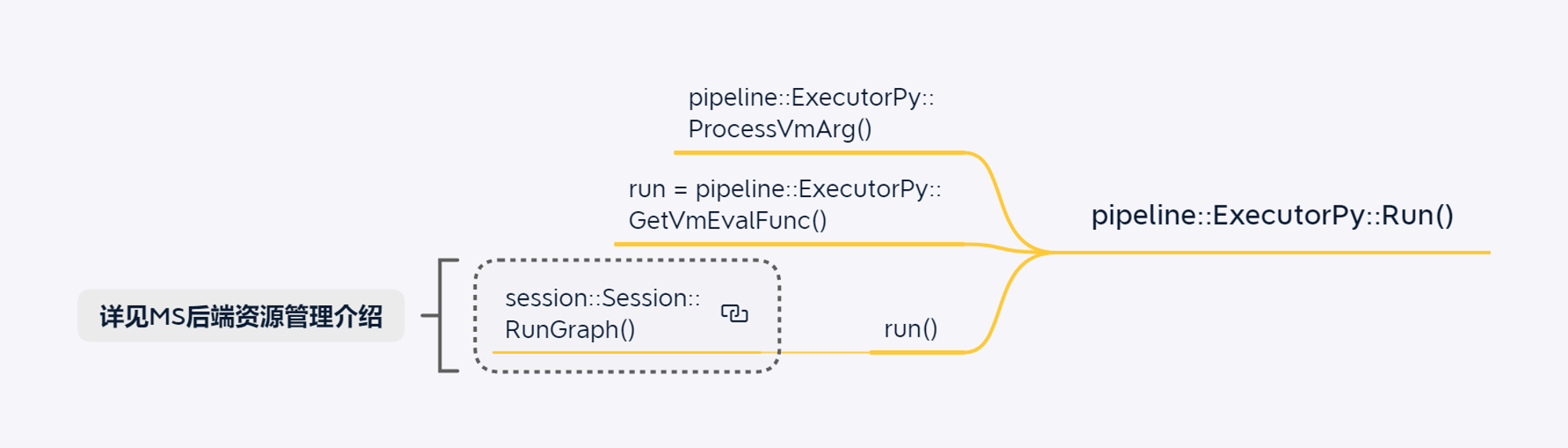
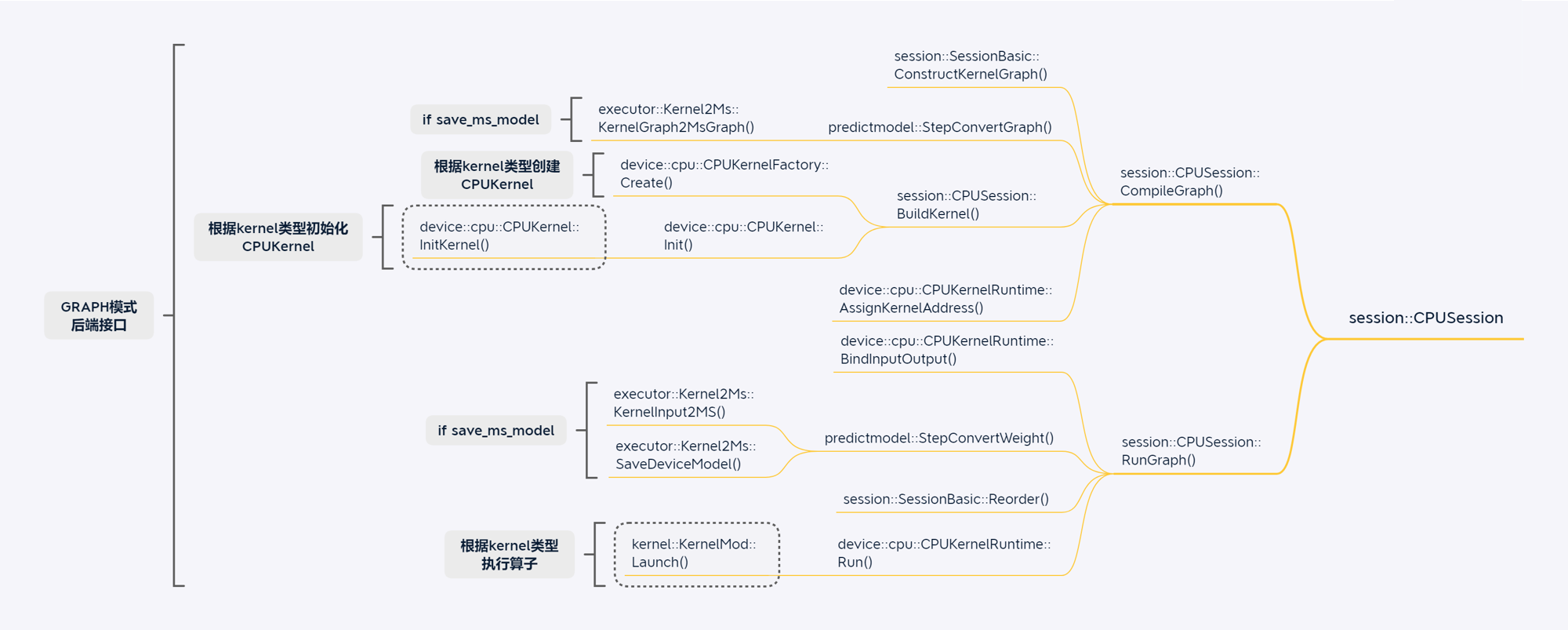
GPU单算子执行场景
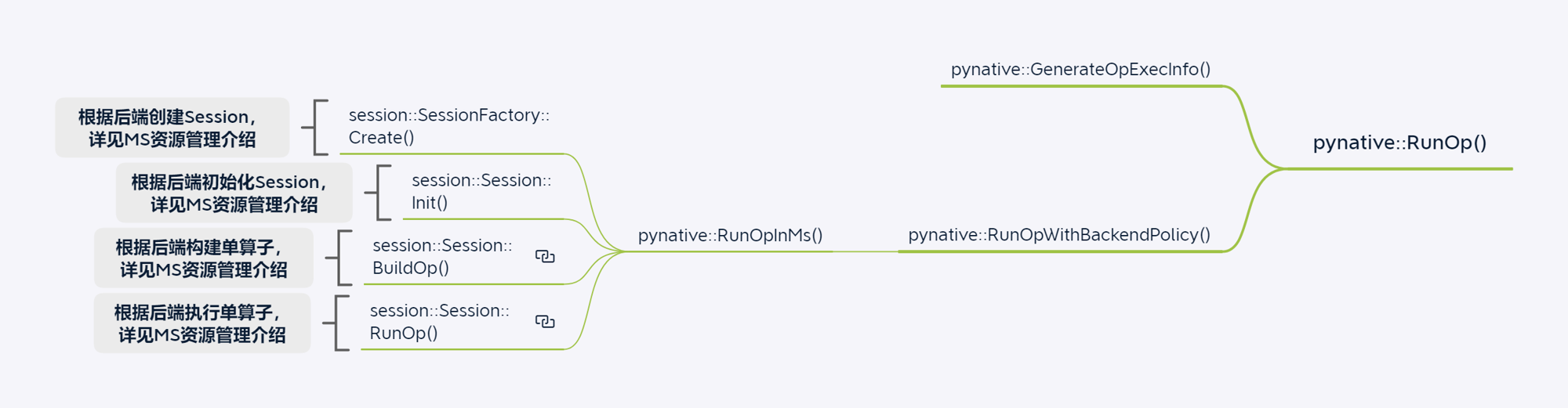
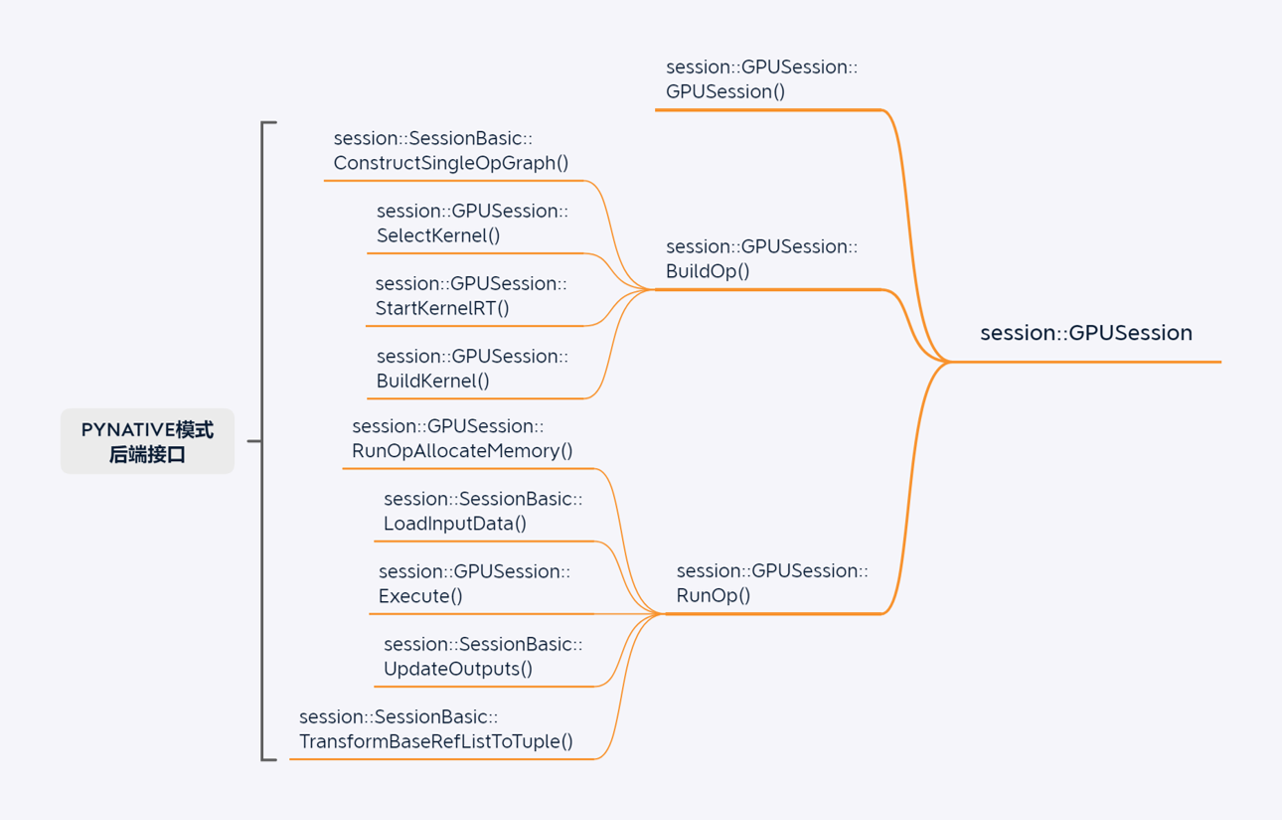
导出ONNX模型场景
写在最后
如上就是针对MindSpore源码的调用流程分析,如有问题请发送邮件至contact@mindspore.cn,或移步至GitHub Issue列表反馈您的问题。